
tg-me.com/knowledge_accumulator/253
Last Update:
Strangely, Matrix Multiplications on GPUs Run Faster When Given "Predictable" Data! [2024]
Человеческая инженерия - забавная вещь. Мы строим очень сложные механизмы, являющимися небоскрёбами из различных абстракций, не держа в голове всевозможные спецэффекты их взаимодействия. Из-за этого при их реальном применении возникают приколы, об одном из которых написан вот этот блогпост.
Оказывается, если взять видеокарту и попросить её умножить 2 большие матрицы фиксированного размера, то скорость выполнения зависит от значений на входе. Казалось бы - количество умножений и сложений фиксированное и такого быть не должно, но разница аж в 10-20%. Как так?
Для понимания этого перескажу некоторые аспекты работы видеокарты (сам не эксперт, пожалуйста, поправьте неточности):
Итак, видеокарта - это конструкция из транзисторов и других элементов, по которым течёт ток (внезапно). Он пропускается через всю схему какое-то количество раз в секунду, и это называется тактовой частотой. На то, чтобы пропускать ток, уходит часть мощности видеокарты - в случае A100 это около 80W.
Эта мощность потребляется видеокартой даже тогда, когда на ней не происходит никаких больших вычислений, что бы GPU ни делала. Когда на видеокарте начинают происходить вычисления, то по ней начинают бегать данные и транзисторы переключают свои значения.
Переключение значения транзистора - это энергозатратная операция. В момент вычислений затраты резко возрастают и становятся выше максимально доступной мощности), из-за чего тактовая частота вынуждена понижаться и вычисления замедляются.
Автор проводит дополнительные замеры - что, если ограничить мощность GPU вручную до меньших значений? Соотношение усугубляется - матрицы из нулей перемножаются аж в 2.2 раза быстрее при ограничении в 150 ватт.
При зафиксированной мощности в 200 ватт, при ограничении частоты в 600 MHz мощности хватает на всё и время работы не зависит от данных. При поднятии скорости это соотношение начинает расти, поскольку в этом случае её хватать перестаёт.
Автор пробует подавать разные виды входов - равномерное распределение, нормальное, нормальное + шахматная маска, бернулли и т.д. - результаты можно найти в посте.
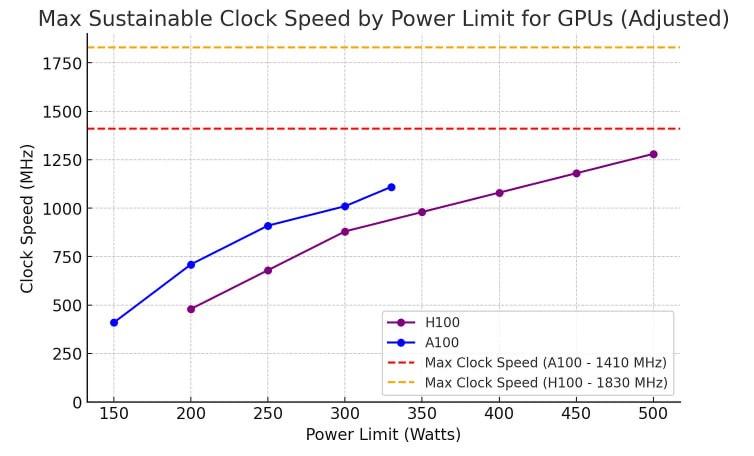
По результатам ещё одного замера удаётся "разоблачить" маркетинг от Nvidia. На бумаге количество флопсов на H100 в 3 раза больше, чем у A100, поскольку считаются они по формуле (кол-во ядер) x (макс. частота) x (флопсы на инструкцию). Однако, по графику видно (прикреплён к посту), что поддерживать такой теоретический максимум видеокарта не способна при доступном лимите мощности
Таким образом, в реальности она работает лишь в 2 раза быстрее. Учитывая то, что их мощности это 700W и 400W, получается, что "реальные" флопсы на ватт между поколениями выросли весь скромно.
Всё это лишь укрепляет мой оптимизм в AI-инжерению. Когда алгоритм будет решать задачу целиком, получая на вход общие ограничения - "спроектируй железку, умножающую случайные матрицы как можно быстрее, с такими-то ограничениями" - результат будет непостижим для нашего глупого мозга, но эффективность всё окупит.
@knowledge_accumulator
BY Knowledge Accumulator
Share with your friend now:
tg-me.com/knowledge_accumulator/253